I am broadly interested in designing and analyzing Privacy-Enhancing Technologies (PETs), which often overlaps with some aspect of cybersecurity. More particularly, my research studies techniques to quantify the privacy leakage of various systems and designs defenses to limit this leakage. I have written this informal page to help interested students understand what I do. For more technical descriptions, please check my papers.
Click on the research lines below to learn more about them.
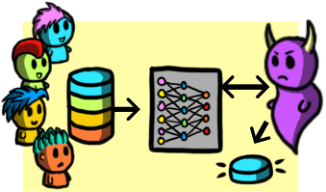
Machine learning technologies are everywhere. Here's the privacy angle of all this: when one builds a machine learning model using a privacy-sensitive training dataset, the model will memorize some privacy-sensitive information. An attacker with access to that model (even if it is just black-box query access) can learn a lot of information about the training data. The most basic attack in this setting is called membership inference attack, where an attacker gets access to a model and a data sample, and wants to guess whether that sample was in the model's training set. More complex attacks include model inversion, where the attacker reconstructs training samples just by querying the model! Sadly, due to the complexity of machine learning (it's called machine learning, after all), preventing these attacks is really hard!
I am interested in understanding the privacy implications of training machine learning models on sensitive data, developing tools to quantify their privacy leakage, and building defenses to limit such leakage. As with the rest of my research, I try to avoid purely empirical or heuristic results, and instead aim get some solid understanding of why things work the way they do. This is sadly somewhat hard in machine learning, but we have to try!
The only paper I have (so far) in the topic should give you a good idea of the type of questions I like to study in this area:
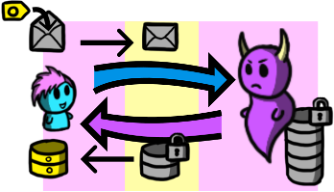
Storing data in the cloud is very convenient: it frees resources on our local devices and provides data availability as long as we have an Internet connection. However, storing privacy-sensitive data in the cloud is somewhat scary: what if the cloud is looking at our data? Can we trust the cloud?
Luckily, we are very good at hiding data using cryptography! We can encrypt of all our data and store it in the cloud. However, if we try to search for any data item, turns out we cannot do this by default if the data is encrypted. Enter searchable encryption!
Searchable encryption enables the storage of encrypted data on a cloud provider, along with cryptographic structures that allow secure searches to be performed on the data. Now, the cloud provider learns nothing about the data itself or how it is accessed. However, total protection incurs a lot of overhead, which means that, in practice, we should leak some information to the cloud provider. Understanding the implications of such leakage and designing systems that limit such leakage (while still being efficient) are two very important questions that my research deals with.
I have looked at this problem by developing attacks against searchable encryption schemes, since the performance of an attack gives us some indication of the privacy level the system provides. If you are curious about this, check my publications below. I recommend starting with the SAP attack, which has enough statistics to show you the kind of work I do. If you liked that, check a more sophisticated attack called IHOP, as well as my produest academic achievement: the slides I used to present this work. There is also a video of that talk somewhere, but please don't watch it.
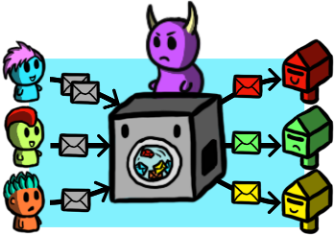
Nowadays, most Internet communications are encrypted, which is great! However, even if your data is encrypted, it is not hard for an adversary to tell where your traffic is going (e.g., that particular website you are visiting). To hide who talks with whom over the Internet (and other meta-data), we need anonymous communications systems. Tor is the most successful of such systems, but there is another type of systems, less known, called mixnets. Mixnets aim to protect against a global passive adversary, which is something that even Tor cannot do. While mixnets were conceived a long time ago, their deployments are very recent.
My research in mixnets focuses on understanding and quantifying the privacy guarantees that they provide. In the past, I have done this from a theoretical perspective, using statistics and signal processing techniques. Recently, we have seen some actual deployments of mixnets (e.g., Nym), and I would love to study the privacy of these specific systems!
Below are my papers on the topic. If you are a student looking for one paper to read on this topic, start with my first paper ever (only four pages, and enough math to scare you off). If you enjoyed that and want to read more math, also give this one a read.
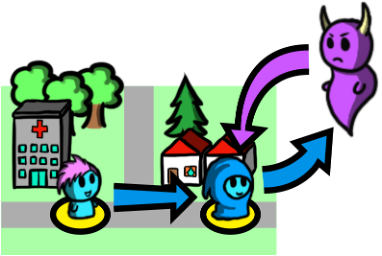
Open your phone, got to location permissions, and see how many apps you are sharing your location with. Probably a lot. Food delivery, rideshare, weather forecast, camera, dating apps, etc. To use most of these apps, we need to share our location data with a service provider. Have you ever wondered how sensitive this information is? With your location information is not only trivial to learn where you live and work, but one could probably infer your hobbies, habits, political preferences, etc. What if the service provider is malicious or does not have the proper safeguards to protect your data? Scary!
My research in location privacy studies location privacy-preserving mechanisms, which partially hide our location to provide some privacy while still being able to get some utility from the service. My work so far has focused on reasoning about which metrics are appropriate to quantify privacy in this case, and studied how to optimize the privacy-utility trade-offs in this setting.
If you want to read one paper about this, I would recommend my CCS'17 paper. Here's the full list:
Besides this, I would be open to explore other privacy problems where my knowledge can be helpful. Basically: if there is a technology that relies on data collected from people, this data can be privacy-sensitive, and we do not know how to measure or prevent the privacy leakage, then that is potentially a problem I want to work on.
I also like doing work that involves differential privacy in some way!